Background
기존모델
RNN, LSTM, 게이트 순환 신경망에서 언어모델과 번역모델에서 sequence 모델링을 사용해왔다.
재귀 모델은 입력의 순차적인 흐름을 통해 hidden states를 만들지만 병렬구조가 불가능 하다.
또한 실제 연관성보다 가까운 위치의 단어끼리 연관성이 무조건 높게 나오기 때문에 정확도가 떨어진다.
Attention 매카니즘으로 만들어진 인코더 디코더의 구조이다.
연속된 기호 X들을 입력으로 받는 encoder가 표현 Z를 decoder로 받아 출력인 기호 Y로 생성한다.
매 순간 모델은 자동 순환하며 이전에 만들어진 기호를 다음 기호를 생성하는데 추가적인 입력으로 받는다.
예를들어 Y의 m번째 기호는 Y m-1번째 기호를 추가적인 입력으로 참고하여 생성된다.
인코더 디코더의 구조는 전체 입력 문장이 하나의 벡터로 압축되는데 여기에 attention이라는 구조를 추가하면 문장의 모든 정보를 고정 길이 벡터로 인코딩 하지 않아도 정보 손실이 일어나지 않는다.
self-attention 을 통해 행렬곱을 사용하여 한번에 병렬처리가 가능하다.
한번의 연산으로 모든 중요한 정보들을 임베딩 한다.
Transformer는 기존의 encoder - decoder 구조는 유지하지만 행렬곱으로 시간을 단축한다.
또한 행렬을 이용할 때 입력의 순서가 뒤섞이기 때문에 position encoding을 통해 위치정보를 저장한다.
Stack 구조를 통해 이 과정이 진행된다.

위의 그림에서
Encoder
- N이 6개인 레이어로 구성
- 각각의 레이어는 2개의 서브 레이어로 구성
multi-head self-attention mechanism
position-wise fully connected feed-forward network
- 서브 레이어의 normalization을 위한 연결이 존재
각각의 서브 레이어의 출력으로 LayerNorm(x + Sublayer(x))
레이어 normalization을 위한 연결을 위해 모든 서브 레이어와 임베딩 레이어의 출력 디멘션은 512로 일원화 한다.
dmodel = 512
Decoder
- N이 6개인 레이어로 구성
- 각각의 레이어가 3개의 서브 레이어로 구성
multi-head self-attention mechanism
position-wise fully connected feed-forward network
masked multi-head attention over the output of the encoder stack
- 서브 레이어의 normalization을 위한 연결이 존재
- masked-multi-head attention
self-attention 하는 경우 값의 처리 이후에 단어를 볼 수 없도록 가린다.
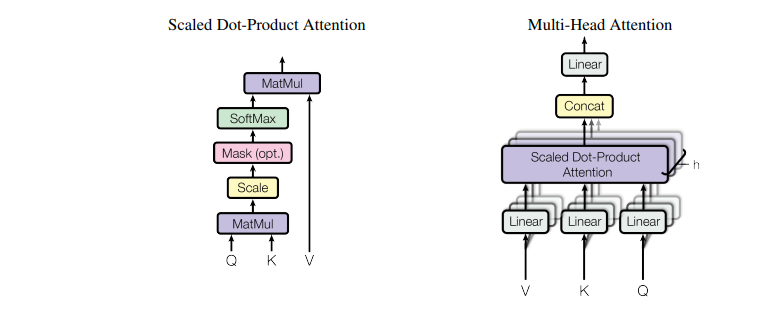
attention 함수는 쿼리 Q와 key-value 쌍의 출력으로 이루어진다.
Query, Key, Value 출력 값은 모두 벡터이다.
출력은 Value의 가중치 합이고, Key와 Query의 호환 함수에 의해 계산된다.
Scaled Dot-Product Attention
input : queries and keys of dimension dk, and values of dimension dv
Query, Key를 통해 attention 가중치를 구하고, Value 값을 곱한다.
그 후에 소프트 맥스 함수를 적용한다.

위의 식에서 dk의 제곱근으로 나누는 것은 dk가 커질 경우 행렬곱의 결과는 더욱 증가하기 때문에 이를 방지하기 위해 나눈다.
또한 self-attention은 Query, Key, Value 값의 출처가 모두 같다.
Query는 decoder의 하나의 셀 값이고, Key, Value 값은 encoder의 모든 시점에서의 셀의 값이다.
Multi-Head Attention
scaled dot-product attention 레이어를 h개 만큼 동시에 실행한다.
이로써 병렬처리가 가능하다.
기존의 512 디멘션을 8로 나눈 64의 디멘션으로 레이어를 실행한다.
h = 8
head1에서 64 디멘션, head2에서 64 디멘션 , ... , head8에서 64 디멘션

입력 벡터를 64 디멘션씩 분할하고 이것을 concat 결합한다.
초기 입력으로 4 디멘션의 단어 벡터가 주어지면
4 X 3의 Query 가중치 벡터, Key 가중치 벡터, Value 가중치 벡터와 곱해져서 3차원의 벡터를 만든다.
Attention을 여러번 수행하여 다양한 시각으로 정보를 수집하게 된다.
Position-wise Feed-Forward Networks
attention 레이어 이외에 인코더와 디코더에 완전연결 순방향 신경망이 포함된다.
rnn 구조가 아니기 때문에 단어의 순서 정보를 포함해야 한다.
Linear Transformation -> 활성함수 Relu -> Linear Transformation
파라미터 W와 b값은 변하지 않는다.
하지만 인코더가 달라지면 다른 파라미터 값을 갖는다.

입력 디멘션 512에서 출력 디멘션 2048로 생성된다.
Self-Attention, Recurrent, Convolutional, 제한된 Self-Attention 레이어 네가지를 비교했다.

Positional Encoding
RNN에서와 달리 Transformer는 병렬적으로 연산을 하다보니 입력 벡터의 순서에 혼동이 생길 수 있기 때문에 위치 정보를 저장하여 사용한다.

이 포지션 인코딩 값은 단어 임베딩 베거와 결합하여 초기 입력으로 사용된다.
레이어를 거치기 전에 초기 단계에 실행된다.




각각의 attention head 가 연관 있는 단어들을 연결한 모습



'논문 Paper' 카테고리의 다른 글
| 논문 요약 AI (0) | 2023.03.15 |
|---|---|
| A Survey on Transfer Learning 전이학습 (0) | 2022.11.19 |
| BART: Denoising Sequence-to-Sequence Pre-training for Natural Language Generation, Translation, and Comprehension 바트 (0) | 2022.11.09 |
| Sequence to Sequence Learning with Neural Networks 시퀀스 투 시퀀스 (0) | 2022.11.04 |
| Deep Residual Learning for Image Recognition 깊은 잔차 학습 이미지 인식 ResNet (1) | 2022.11.03 |