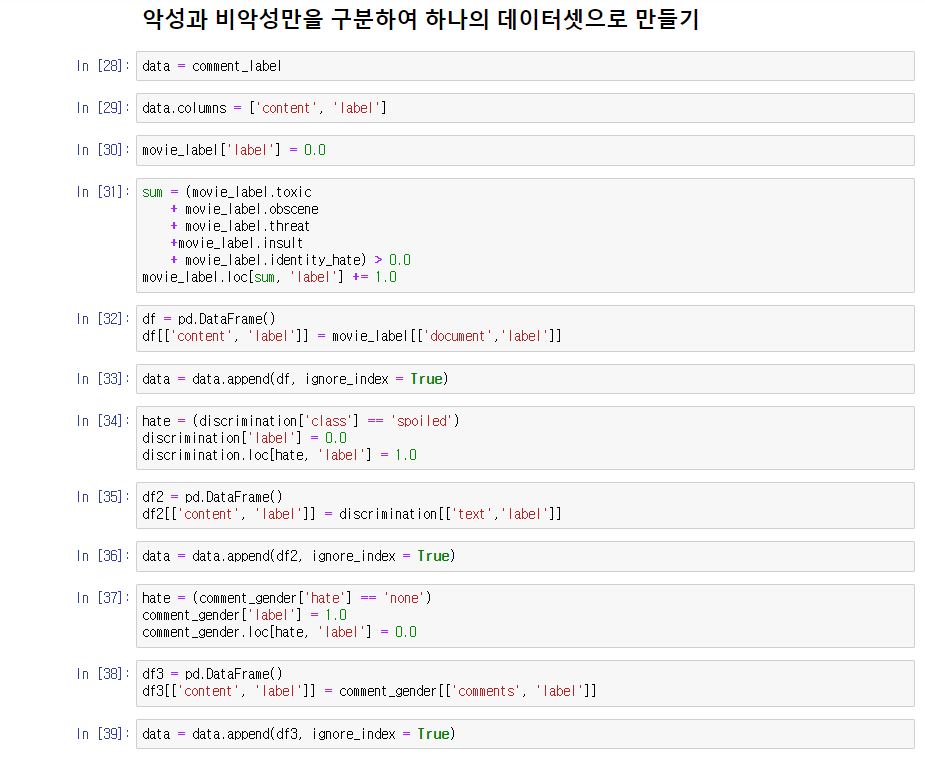
라이브러리


data - 사용한 데이터 전체
notes - 설명 pdf
soynlp - 전처리기
test - 각종 테스트 결과
tutorials - 사용법
attributes
Readme.md
setup

챗봇
텔레그램 챗봇
[챗봇] 파이썬 텔레그램 챗봇, 이것만 따라하면 20분 완성 (코로나 알리미 봇)
텔레그램은 챗봇을 만들기 매우매우 쉬운 편입니다. 이 포스팅을 따라하면, 다른 것 볼 필요 없이 챗봇을 만들어 볼 수 있습니다. A. 텔레그램 앱 설치 안드로이드의 구글 플레이스토어나 iOS의
py-son.tistory.com
카카오 챗봇
https://badaturtle93.tistory.com/15
[Python] 파이썬코드로 챗봇 만들기 (with. kakao i developer)
예전에 파이썬 자료분석 수업 과제로 만들었던 챗봇!! 먼저 전체코드를 공개 ㅎㅎㅎ 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43..
badaturtle93.tistory.com
https://givemethesocks.tistory.com/85
[KAKAO + FLASK] 카카오 챗봇 만들기 (3) - API 서버 연동
0. 들어가기 -. 이번 포스팅에선 카카오챗봇과 API 서버 (이 글에서는 앞서 포스팅한 FLASK를 이용한다)의 연동을 하여 조금 더 자유로운 챗봇 출력을 해본다. -. FLASK를 이용한 다양한 (글, 사진, etc.)
givemethesocks.tistory.com
카카오톡 승인 필요
디스코드 챗봇
챗봇, 웹 API -> API 서버를 만들기 까지 동일하게 진행
챗봇 구현이 더 가능성 있다.
웹 API
모델을 API로 만드는 작업을 Model Serving이라고 한다.
직접 웹서버를 올리는 방법 외에 Docker나 Kubernetes를 활용하는 방법이 있다.
메모리에 올라가 있는 Data 전체를 dump라고 load를 통해 외부에 저장하고 사용하는 것 -> Pickle
Docker를 활용하여 딥러닝/머신러닝 환경을 10분만에 구성하고 jupyter notebook 원격 연결하기
Docker를 활용하여 딥러닝/머신러닝 환경을 10분만에 구성하고 jupyter notebook 원격 연결하는 방법에 대하여 알아보겠습니다.
teddylee777.github.io
https://tutorials.pytorch.kr/intermediate/model_parallel_tutorial.html
단일 머신을 사용한 모델 병렬화 모범 사례 — PyTorch Tutorials 1.11.0+cu102 documentation
Note Click here to download the full example code
tutorials.pytorch.kr
'포트폴리오 Portfolio > AI Project' 카테고리의 다른 글
| 혐오 발언 식별 다썰어 프로젝트 (0) | 2022.05.25 |
|---|---|
| Cuda Nvidia GPU 로컬에서 사용하여 훈련 (0) | 2022.04.29 |
| 모델링 방법 조사 BinaryClassification, Multi label, Multi class Classification (0) | 2022.04.12 |
| AI Project NLP 악플 데이터 셋 일부 proprocessing eda (0) | 2022.04.01 |
| 악플 데이터 셋 추가 (0) | 2022.03.30 |