
언어모델의 목표
Please turn your homework
이후에 in이 나와야 할까 the가 나와야 할까?
all of a sudden I notice three guys standing on the sidewalk
on guys all I of notice sidewalk three a sudden standing the
두 문장 중 나타날 확률이 높은 것은 무엇일까?
언어 모델의 목표는 이와 같이 문장이 일어날 확률을 구하는 것이다.
언어모델의 활용
기계번역 machine translation
P(high winds tonight) > P(large winds tonight)
맞춤법 검사 spell correction
The office is about fifteen minutes from my house
P(about fifteen minutes from) > P(about fifteen minuets from)
음성인식 speech recognition
P(I saw a van) > P(eyes awe of an)
언어 모델 Language Model
연속적인 단어들 sequence of words에 확률을 부여하는 모델

연속적인 단어들이 주어졌을 때 그 다음 단어의 확률을 구한다.
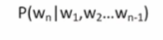
결합확률 Joint Probability
P(its, water, is, so, transparent, that)
Chain rule을 사용한다.
조건부 확률




조건부 확률로 언어모델을 만드는 것은 문제가 있다.
가능한 문장의 개수가 너무 많고, 계산할 수 있는 충분한 양의 데이터를 찾기 어렵기 때문이다.
Markov Assumption
한 단어의 확률은 그 단어 앞에 나타나는 몇개의 단어들에만 의존한다는 가정을 적용한다.


Unigram
이전에 나온 단어와 지금 나오는 단어는 연관이 없다라는 전제로 만들어진 조건부 확률 모델이다.
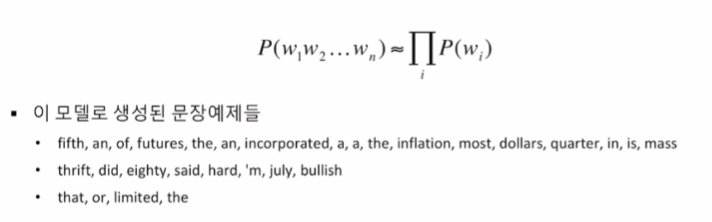
Bigram
Unigram에서 발전하여 바로 앞의 단어에만 영향을 받는다는 전제로 만들어진 조건부 확률 모델이다.

N-gram Model
trigrams, 4-grams, 5-grams로 영역을 확장할 수 있다.
여전히 멀리 떨어진 단어들간의 관계 long distance dependencies를 완벽하게 모델링 하기는 어렵다.
하지만 대다수의 경우 n-gram 만으로 좋은 결과를 보일 수 있다.
'인공지능 AI > 자연어처리 NLP' 카테고리의 다른 글
| NLP 단어 임베딩 (0) | 2022.03.18 |
|---|---|
| NLP 문서분류 감성분류 주제분류 규칙기반모델 snorkel Naive Bayes (0) | 2022.03.18 |
| NLP 언어모델 N-grams 조건부 확률 계산 MLE perplexity 평가 (0) | 2022.03.16 |
| 텍스트 전처리 NLP BPE WordPiece Subword Tokenization (0) | 2022.03.15 |
| Colab NLP torchtext 자연어 처리의 전처리 (0) | 2022.02.16 |