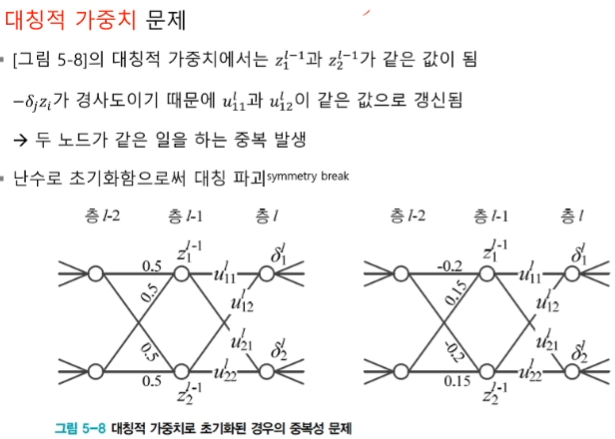
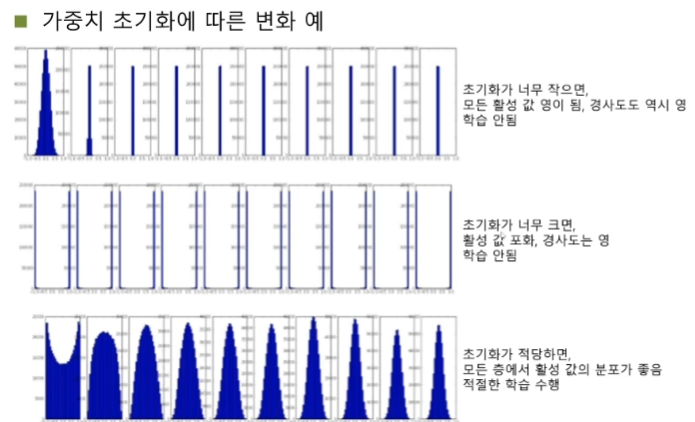
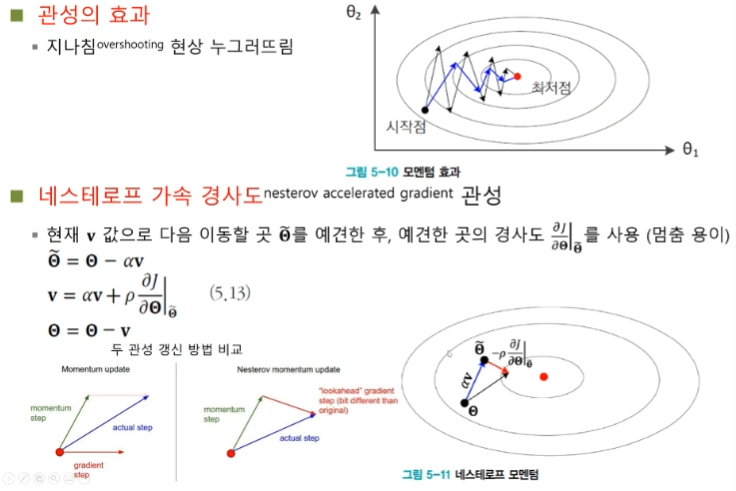
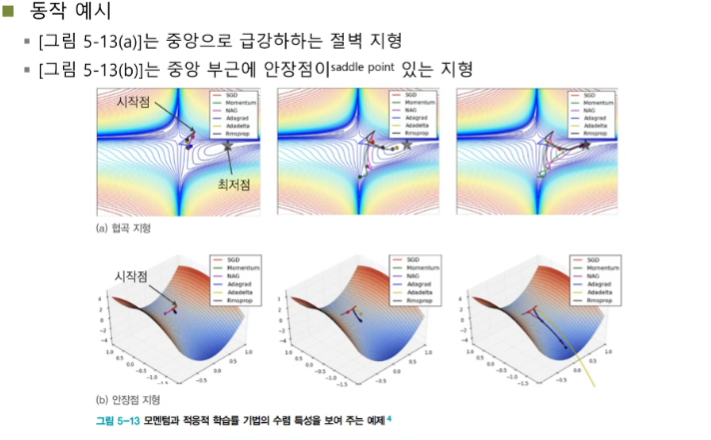
심층학습 최적화를 위한 다양한 방법들을 소개한다. 절대적인 기준이 아니지만 일반적인 방법들이다. 1. 목적함수 (손실함수) - 이전 게시물로 작성했다. 2. 데이터 전처리 3. 가중치 초기화 4. 탄력 (가속도, 관성) 5. 활성함수 6. 배치 정규화 데이터 전처리 Preprocessing 데이터 feature들의 스케일을 비슷하게 맞춰주어야 한다. 이런 문제를 해결하기 위해 정규화 Normalization 를 진행한다. 데이터의 분포를 알 수 있고, 양수나 음수 한쪽으로 치우치는 문제를 해결할 수 있다. 또한 한쪽의 노드로 끌려가는 현상을 방지할 수 있다. 가중치 초기화 Weight Initialization 초기 가중치 값을 어떤 값으로 설정하는 지가 중요하다. 탄력 (가속도, 관성) Momentum..
평균제곱오차 MSE 오차가 클 수록 e 값이 크므로 벌점(정량적 성능)으로 활용된다. 하지만 허점이 존재한다. 경사도를 계산하면 왼쪽의 경사도가 더 크지만 더 많은 오류가 있는 상황이 더 낮은 벌점을 받았다. 교차 엔트로피 Cross Entropy 소프트맥스 함수 Softmax 출력층의 활성함수로 로지스틱 시그모이드와 softmax를 비교한다. 출력층의 변화에 따라 소프트맥스의 결과도 최대 출력에 더 가까워진다 따라서 부드러운 최대 함수로 불린다. 소프트맥스함수와 교차엔트로피 목적함수 로그우도 손실함수에서 교차 엔트로피가 최소화 됨
생성모델 Generative Model 눈을 감고 황금 들녁을 상상했을 때 근사한 영상이 떠오른다면 머리속의 '생성모델' 이 작용했기 때문이다. 사람의 생성 모델은 세상에 나타나는 현상들을 오래 지켜보고 학습한 결과이다. 기계학습이 훈련집합을 통해 비슷한 생성모델을 구축할 수 있다면 강한 인공지능 Strong AI 에 더 다가설 수 있다. 생성 모델은 분별 모델에 비해 데이터 생성과정에서의 심도 깊은 이해가 필요하기 때문이다. 특징 벡터가 2차원이고 이진값을 가비며, 2개의 부류라고 가정하면 훈련집합은 다음과 같다. 이것을 생성모델이 추정하는 확률 분포로 표현하면 실제 상황에서 생성모델은 현실에 내재한 데이터 발생 분포를 알아낼 수 없다. 다양한 생성 모델 GAN 생성기 Generator G와 분별기 D..
ResNet 잔류 학습 Residual Learning 개념을 사용하여 성능 저하를 피하면서 층 수를 대폭 늘린 구조이다. CNN에서 가중치 학습이 제대로 안되어 있다. 이런 부분들을 나눠서 학습시키는 것이 잔류학습이다. 잔류학습은 지름길 연결된 x를 더한 F(X) + X에 감마를 적용한다. 감마*(F(X) + X) 지름길 연결을 하는 이유 - 깊은 신경망도 최적화가 가능 단순한 학습의 관점 변화를 통해 신경망의 구조를 변화 단순 구조의 변경으로 매개변수 수에 영향이 없다. 덧셈연산만 증가하므로 전체 연산량 증가도 미비하다 - 깊어진 신경망으로 인해 정화도 개선이 가능함 - 경사소멸 문제 해결 가장 많이 쓰이는 모델이다.
GoogLeNet의 구조 인셉션 모듈 Inception Module로 되어있다. 수용장의 다양한 특징을 추출하기 위해 NIIN의 구조를 확장하여 복수의 병렬적인 컨볼루션 층을 가진다. 가변적인 크기의 커널을 사용한다. NIN 구조 기존 컨볼루션 연산을 MLP 컨볼루션 연산으로 대체 - 커널 대신 비선형 함수를 활성함수로 포함하는 MLP를 사용하여 특징 추출에 유리하다 신경망의 미소신경망 Micro Neural Network가 주어진 수용장의 특징을 추상화 시도 전역 평균 풀링 Global Average Pooling 사용 이 NIN 개념을 확장한 신경망이 GoogLeNet 인셉션 모듈 마이크로 네트워크로 Mlpconv 대신 네종류의 컨볼루션 연산을 사용하여 다양한 특징을 추출한다. 1*1 컨볼루션을 사용..
VGGNet의 구조 작은 신경망이 좋다는 아이디어에서 시작 3*3의 작은 커널을 사용 신경망을 깊게 만든다 컨볼루션층 8 ~16개를 두어 AlexNet의 5개에 비해 2, 3배 깊어졌다. 16층의 VGGNet - 16 컨볼루션층 13층 완전신경층 3층 작은 커널의 장점 GoogLeNet 의 인셉션 모듈처럼 이후의 깊은 신경망 구조에 영향을 준다 큰 크기의 커널은 여러개의 작은 크기의 커널로 분해 될 수 있다. 이것을 통해 매개변수의 수는 줄어들고 신경망은 깊어지는 효과가 있다. VGGNet 에서는 적용실험을 했지만 최종 선택하지 않은 1*1 커널이라는 것도 있다. 가로 세로 크기가 1이지만 깊이는 원래의 것과 같다. 이것으로 인해 차원의 통합을 이뤄서 3차원을 2차원으로 축소 가능하다. 차원 축소를 거쳐..
AlexNet의 구조 컨볼루션층 5개와 완전연결층 3개로 이루어진 구조 8개 층에 290400 - 186624 - 64896 - 43264 - 4096 - 4096 - 1000개의 노드 배치 컨볼루션층은 200만개 FC층은 6500만개 가량의 매개변수 완전연결층에 30배 많은 매개변수가 있다. 이 이후에 등장한 CNN구조는 완전 연결층의 매개변수를 줄이는 방향으로 발전했다. 등장 당시에 GPU의 메모리 크기 제한으로 인해 GPU#1, GPU#2 로 분할하여 학습을 수행했다. 3번째 컨볼루션 층은 이 두개의 GPU 연산결과를 함께 사용한다 inter - GPU connections 컨볼루션층을 큰 보폭으로 다운샘플링한다. AlexNet은 ImageNet 이라는 대규모 사진 데이터와 GPU를 사용한 병렬처리..