
컴퓨터 비전 Computer Vision
음성 인식 Speech Recognition
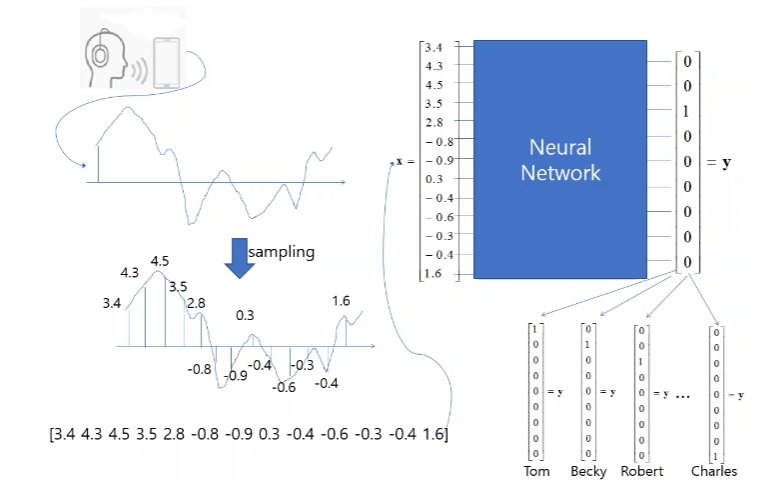
전기 신호로 들어온 음성을 디지털로 메모리에 저장하게 되며 이 과정에서 샘플링을 하게 된다.
숫자로 표현된 샘플들은 중간에 생략된 과정들을 거쳐 벡터로 치환하여 신경망을 통해 처리한다.
신경망과 분류과정을 거쳐서 누구의 음성인지 파악할 수 있게 된다.
영상 인식 Visual Recognition

흑백 영상은 화소 하나씩이 하나의 값이 된다.
모든 위치의 값을 밝기와 비례한 숫자 값으로 치환하여 밝을수록 255에 가까운 값을 가지고, 어두울수록 0과 가까운 값을 가지게 된다.
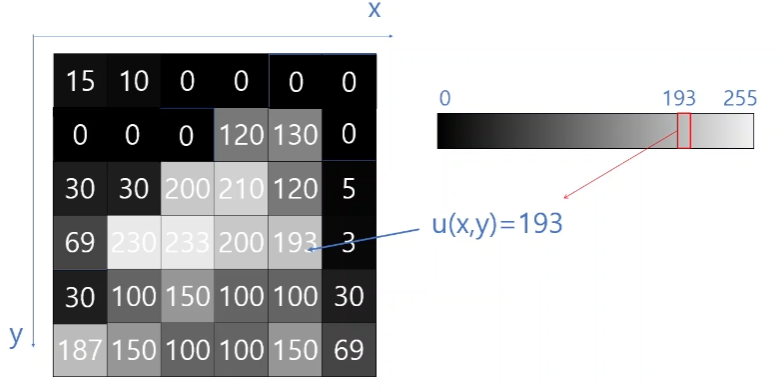
각 구역은 x와 y의 좌표 값으로 위치를 알게 되고 그 위치의 값인 U(x, y) 가 밝기 값을 가지는 요소가 된다.
2차원의 밝기 값으로 나타낸 이 흑백의 벡터는 한가지 밝기 값을 갖는 디지털 영상이다.
만약 RGB 값으로 표시한다면 한 위치당 3개의 밝기 값을 가지게 된다.
R 채널, G 채널, B 채널을 가진 것은 컬러 디지털 영상이다.
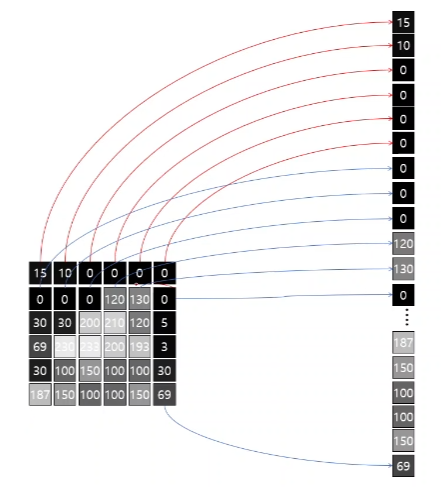
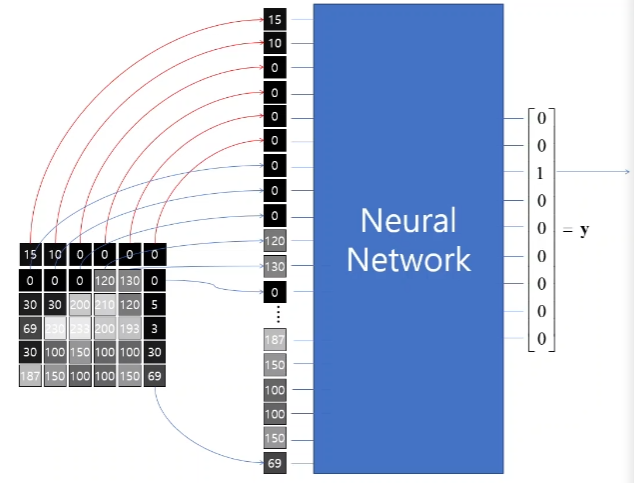
이 벡터값들을 일직선으로 나란히 배열한 후 만들어진 1차원 벡터를 신경망을 거쳐서 분류기에 도달하면 사진의 특성을 파악할 수 있다.
어떤 물체가 담겨져 있는지, 어떤 상황인지, 이상 반응이 있는 사진인지 등등 알수 있다.
처음에 벡터를 추출하는 부분만 다를 뿐 음성인식과 영상인식은 비슷한 부분이 많다.
인식의 문제
인식, 예측의 문제는 분류 Classification과 회귀 Regression의 문제로 귀결된다.
음성인식
- 사람의 목소리를 분류하여 새로운 음성이 어디에 해당하는지 판단
영상인식
- 영상을 분류하여 새로운 영상이 어디에 해당되는지 판단
입력 : X
출력 : F(X)
출력값 F(X)가 label y(true)와 비슷해지는 매핑 F(X)를 찾는다.

인간과 강아지를 구분하는 과정이다.
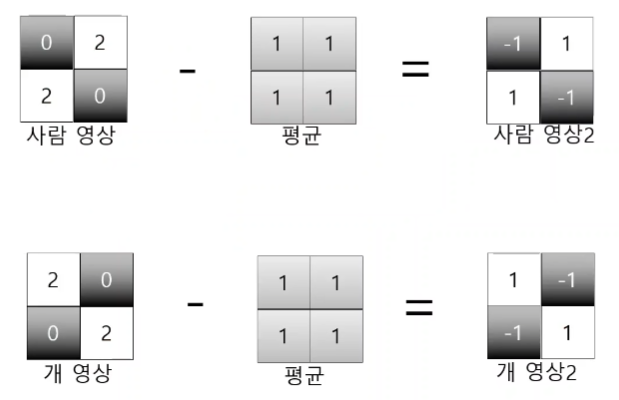
사람과 강아지의 영상에서 벡터를 구하고, 전처리로 평균값을 뺀다.
정규화 과정의 약식이다.
벡터 각 위치의 값이 신경망의 값과 곱해져서 결합한다.
이 값은 A값과 B값으로 구분된다.
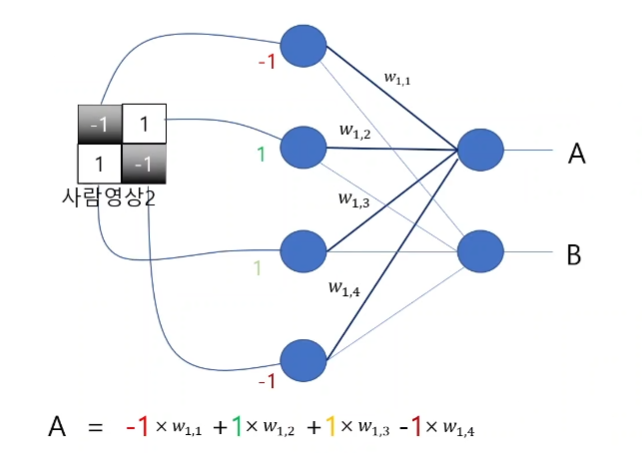
각각 -1과 1의 값을 가지고 있다.
A가 사람이라는 분류일 때, 전체 계산된 결과는 B값보다 커야 한다.
W의 값들이 모두 -1이나 1만 존재한다면.
그 말은 -1과 곱하는 W11, W14의 값이 음수인 -1이며 1과 곱하는 W12, W13의 값이 1인 양수여야 한다는 것을 의미한다.
이런 가중치 W값 Weight가 A노드를 Activate 시킨다고 한다.



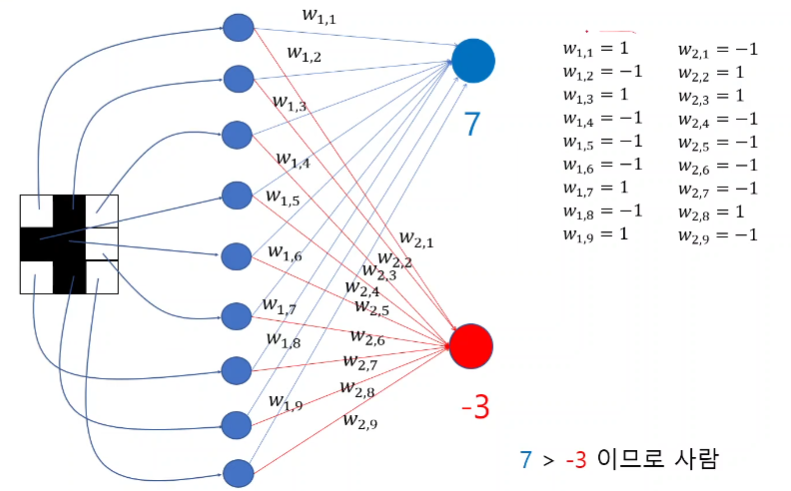
개 영상에 맞는 B노드를 값을 Activate 했을때 그에 맞는 가중치 값들을 다시 모아서 보면, 개영상에서 추출한 벡터와 흡사하다.

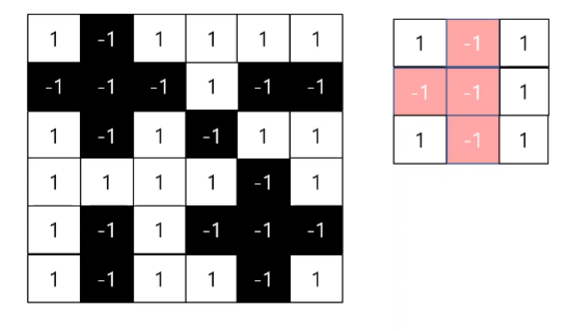
영상에서 사람과 강아지를 분류하는데 만약에 신체 일부가 없는 사람이나, 다리가 없는 강아지를 인식한다면 어떨까.
분류기의 정확도는 낮아지지만 올바른 분류를 해낸다.
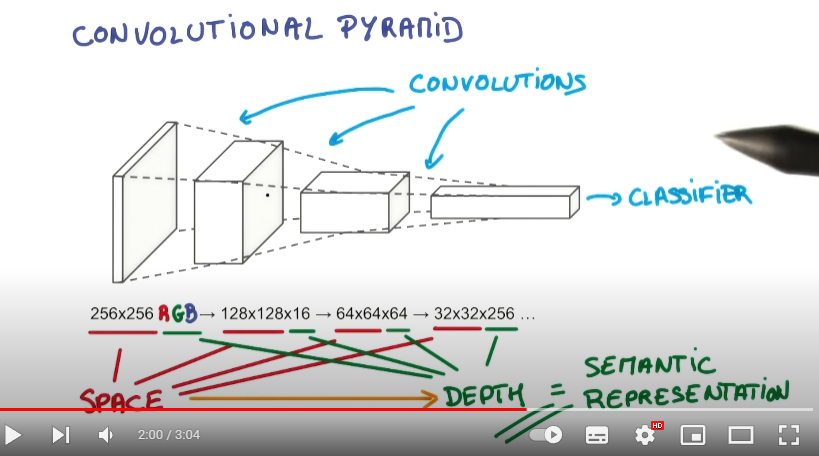
컨볼루션 신경망 CNN
Convolution Neural Network으로 영상과 필터간의 컨볼루션을 진행한다.

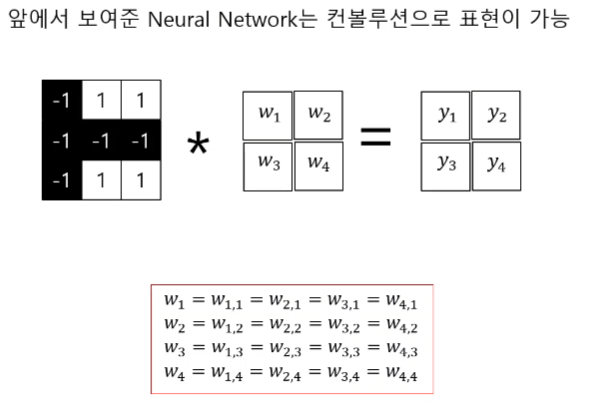
필터와 가장 유사한 부분이 큰 값이 나온다.
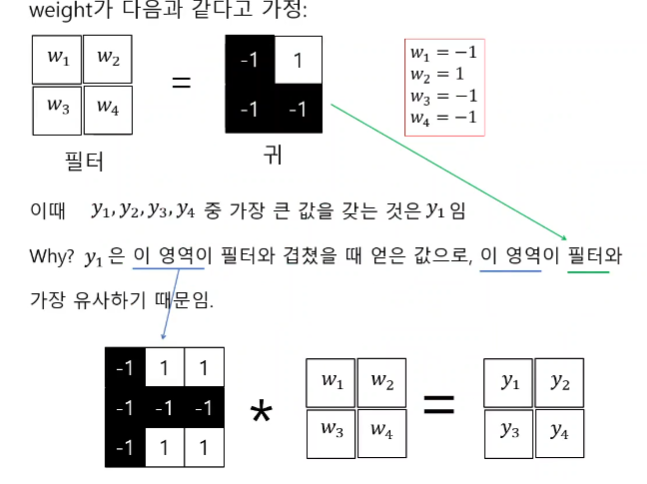
그래서 영상의 Y1 부분에 귀가 있다는 것을 알 수 있다.
이런식으로 귀, 눈, 얼굴 등의 여러가지 필터를 적용하면서 영상에서 값을 추출하여 위치를 파악할 수도 잇다.
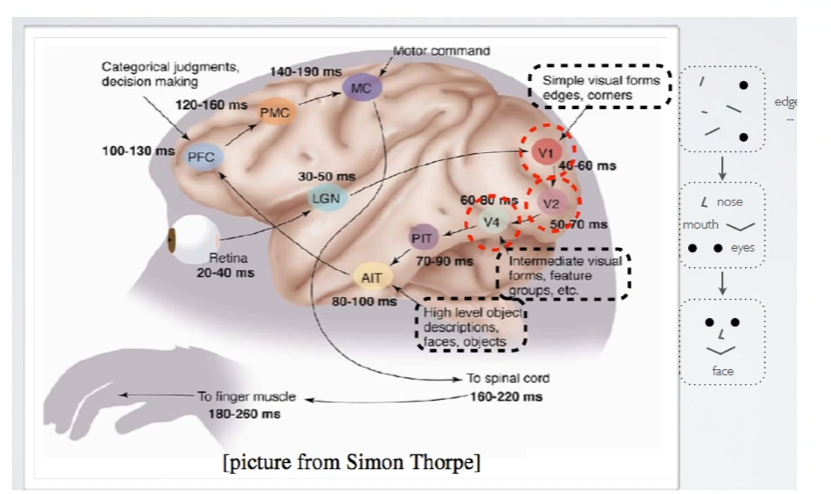
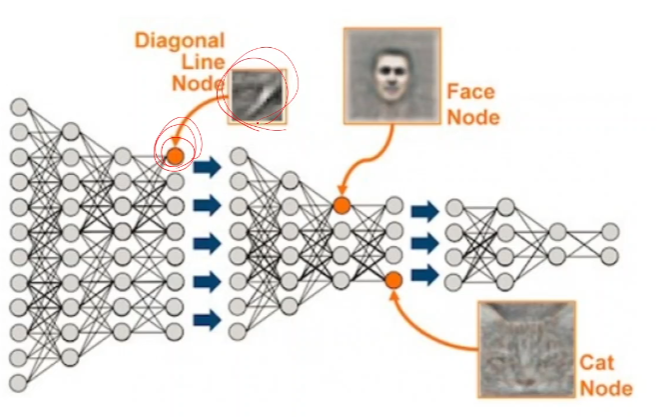
레이어의 단계가 높아질수록 추상화된 피쳐들을 추출한다.

멀티채널 컨볼루션 Multi Channel Convolution
여러가지 색상을 나타낼 수 있는 RGB 컬러 채널을 벡터와 하여 필터를 적용한다.
컬러 채널이 3가지라면 영상 1칸당 3개의 벡터가 생성되고 이것을 필터와 연산하여 레이블을 만들어낸다.
CNN에서 output channel의 개수는 필터의 개수와 같다.
만약 64개의 필터를 적용한다면, 64개의 output이 나온다.
필터가 슬라이딩 하면서 Output을 만들어낸다.
k개의 필터로 조금씩 세로로 쌓아나간다.
https://www.youtube.com/watch?v=jajksuQW4mc
쭈우우욱 핀다..
컨볼루션은 벡터의 형태를 변형할 수 있기도 하다.
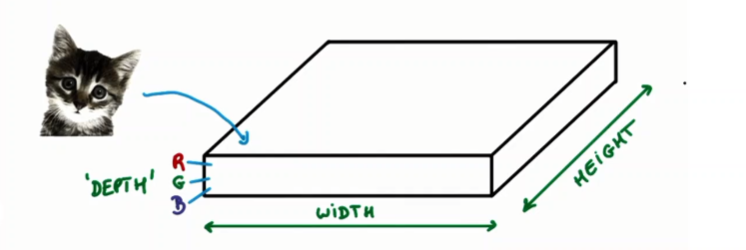
input [ batch, height, width, in channels]
depth는 필터의 개수와 같다.
filter [ height, width, in channels, out channels = depth]
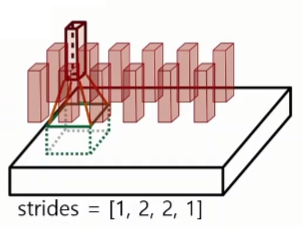
Stride로 모든 면을 컨볼루션 연산하지 않고 칸을 건너뛰면서 연산한다.
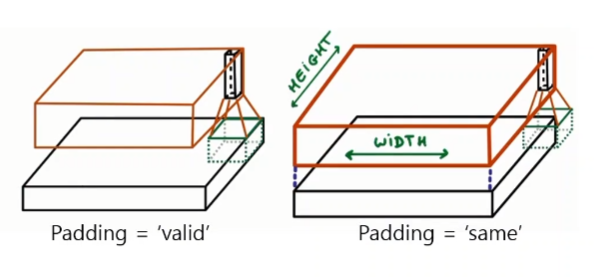
패딩으로 같은 사이즈를 유지해준다.
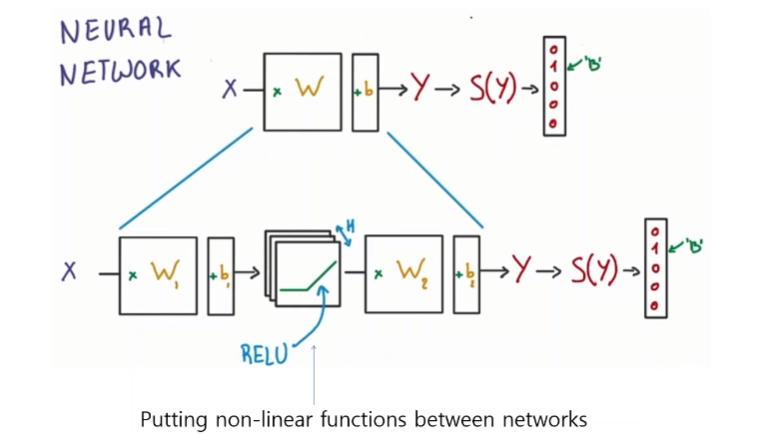
활성함수로는 시그모이드 Relu 등을 사용한다.
요즘은 거의 Relu를 사용한다.
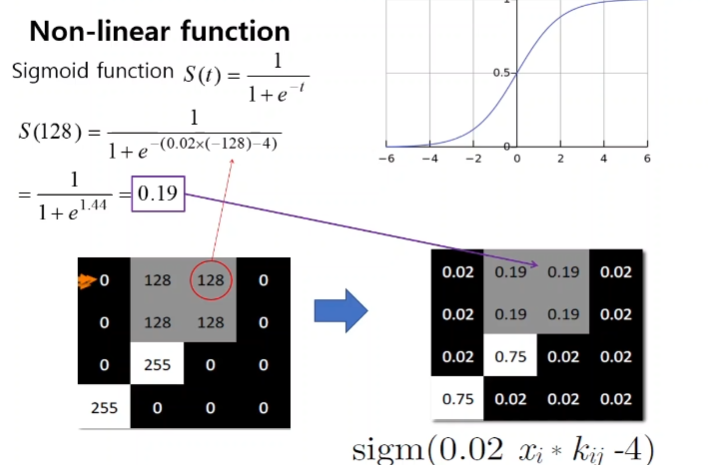
값을 0과 1사이의 값으로 완만하게 만들어준다.

'인공지능 AI > Visual' 카테고리의 다른 글
| Mask - RCNN Semantic Segmentation Object Detection (0) | 2022.03.29 |
|---|---|
| Pose and Face Estimation Visual Recognition (0) | 2022.03.28 |
| Semantic Segmentation PSPNet Unet 영상인식 (0) | 2022.03.28 |
| Semantic Segmentation FCN AlexNet 보간법 FCN-8s (0) | 2022.03.28 |
| Semantic Segmentation 의미론적 분할 (0) | 2022.03.28 |