
빅데이터
- 서버 한대로 처리할 수 없는 규모의 데이터
2012 04 아마존 클라우드 컨퍼런스에서 데이터 사이언티스트 존 브라우저가 내린 정의
분산 환경이 필요한가?
- 기존의 소프트웨어로는 처리할 수 없는 규모의 데이터
소프트웨어 오라클, MySQL과 같은 관계형 데이터 베이스가 감당할 수 없는 규모
분산 환경에 대해 생각해 보지 않은 기존의 시스템
Pandas로 감당할 수 없을 정도의 크기의 엄청난 양의 데이터?
빅데이터 4V
Volume : 데이터의 크기가 대용량인지
Velocity : 데이터의 처리 속도가 중요한지
Variety : 구조화된 데이터, 비구조화된 데이터 모두 존재하는지
Veracity : 데이터의 품질이 좋은지
모바일 디바이스의 위치정보
스마트 TV
센서 데이터
네트워킹 디바이스
웹페이지
사용자 검색어
클릭정보
계속 정보들을 쌓아가면 데이터는 무한 증식하게 되고 관리가 쉽지 않다.
구글이 빅데이터 기술의 발전을 위해 외부에 대용량 처리 시스템을 발표하게 되었다.
그 이후로 분산 처리 시스템 하둡과 스파크 등이 등장하기 시작했다.
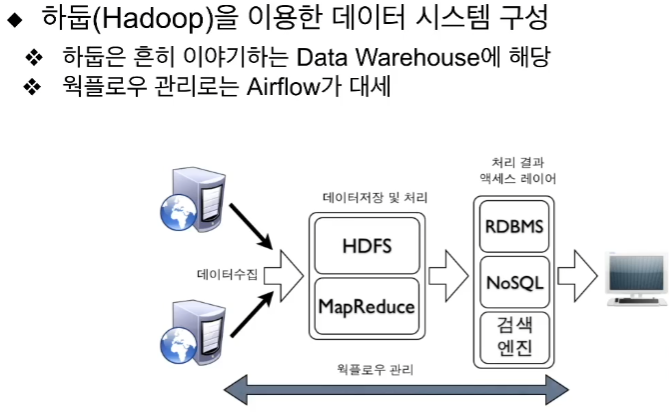
Hadoop
구글에서 발표한 대용량 처리기술 논문 2개를 바탕으로 등장한 시스템
2003 The Google File System
2004 MapReduce : Simplified Data Processing on Large Cluster
대용량 처리 기술
분산 파일 시스템 HDFS , 분산 컴퓨팅 시스템 MapReduce
- 분산 환경 기반으로 1대 이상의 서버로 구성
분산 컴퓨팅과 분산 파일 시스템 구비
- Fault Tolerance
소수의 서버가 고장나도 동작해야 한다.
- Scale Out
서버를 확장해 나가는 것이 용이해야 한다.

하둡 1.0은 HDFS위에 MapReduce라는 분산 컴퓨팅 시스템이 있는 구조였다.
하지만 다른 분산 컴퓨팅 시스템은 지원하지 못한다.
하둡 2.0에서 아키텍쳐가 변경되어 기반 분산처리 시스템이 되었고, 그 위로 애플리케이션 레이어가 올라가는 구조가 되었다.
Spark는 하둡2.0에서 애플리케이션 레이어로 실행된다.

HDFS 분산 파일 시스템
데이터를 128MB 블록 단위로 저장한다
Fault Tolerance를 보장할 수 있는 방식으로 각 블록은 데이터 노드로 3군데 서버에 중복 저장된다.
이 세군데의 서버의 저장된 주소와 정보들은 내임노드라는 부분에 저장된다.
이 내임노드는 세컨더리라는 백업이 있다.
분산 컴퓨팅 시스템
잡트래커 하위로 태스트 트래커 3군데가 있다.
잡 트래커가 일을 나눠 다수의 태스크 트래커에 분배한다.

'SQL > Spark, Hadoop' 카테고리의 다른 글
| Spark colab 타이타닉 데이터 Pipeline ML Evaluation GBT (0) | 2022.03.13 |
|---|---|
| Spark 타이타닉 데이터 분석 MLib feature 변환 imputer, minmax scale, vector assembler (0) | 2022.03.13 |
| Taipei Housing ML Spark Colab 주택 가격 예측 모델 선형회귀 (0) | 2022.03.05 |
| Spark 외부 데이터베이스 연결 AWS Redshift colab (0) | 2022.03.03 |
| Spark colab 실습 apple data (0) | 2022.03.03 |